Pandas进阶
本章介绍pandas层次化索引,索引的堆(stack),以及多层索引聚合操作,拼接操作
创建多层行索引
隐式构造
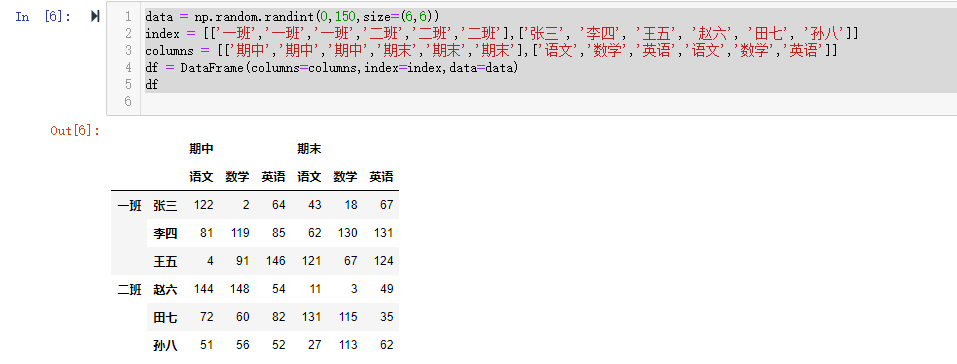
最常见的方法是给DataFrame构造函数的index参数传递两个或更多的数组
1 | data = np.random.randint(0,150,size=(6,6)) |
- Series也可以创建多层索引
1 | index = [['一班', '一班', '一班', '二班', '二班', '二班'], ['张三', '李四', '王五', '赵六', '田七', '孙八']] |

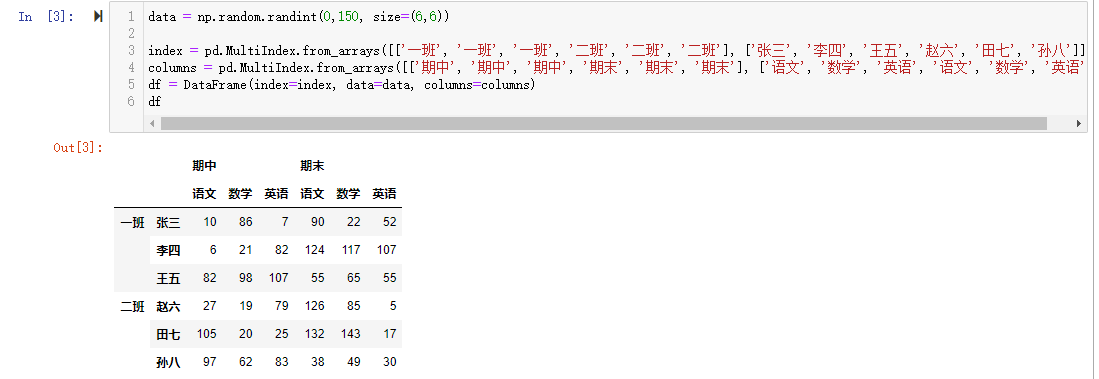
显示构造pd.MultiIndex
- 使用数组
1 | data = np.random.randint(0,150, size=(6,6)) |
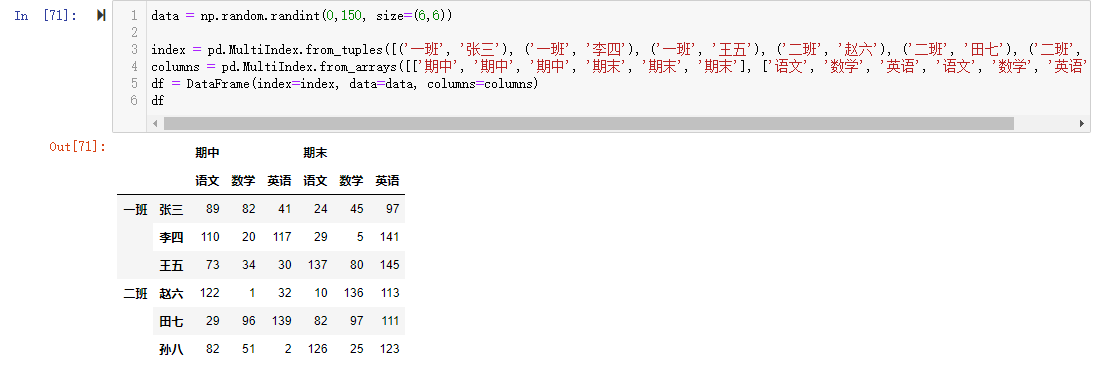
- 使用tuple
1 | data = np.random.randint(0,150, size=(6,6)) |
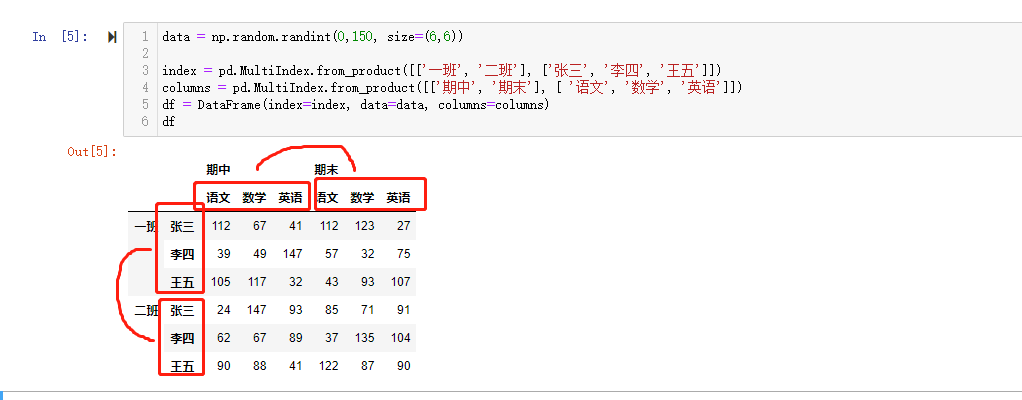
- 使用product
1 | data = np.random.randint(0,150, size=(6,6)) |
多层索引对象的索引与切片操作
Series的操作
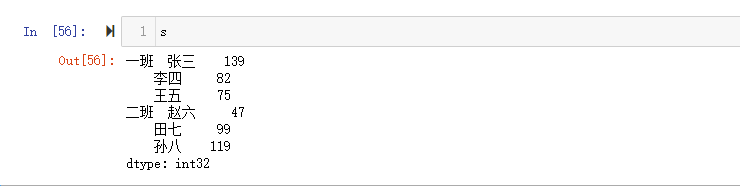
【重要】对于Series来说,直接中括号[]与使用.loc()完全一样,推荐使用中括号索引和切片。
索引
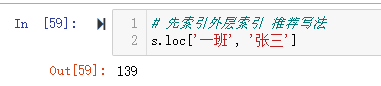
原则: 当有多层索引的时候,不要直接索引内层索引.
1 | # 先索引外层索引 推荐写法 |
切片
DataFrame的操作
可以直接使用列名称来进行列索引
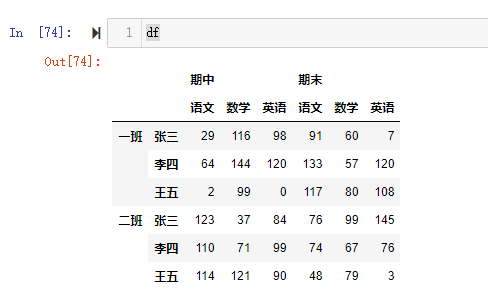
行多级索引的索引和切片操作

列多级索引的索引和切片操作
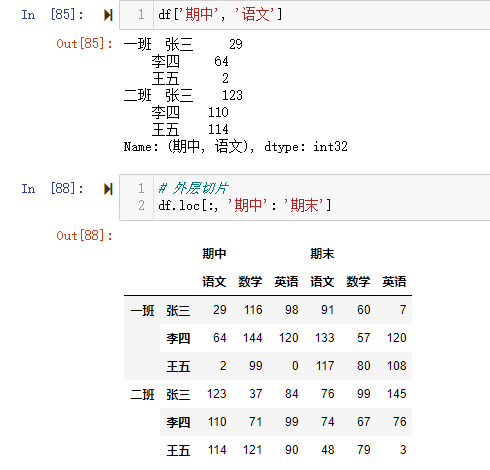
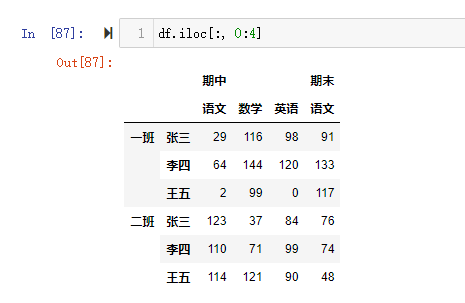
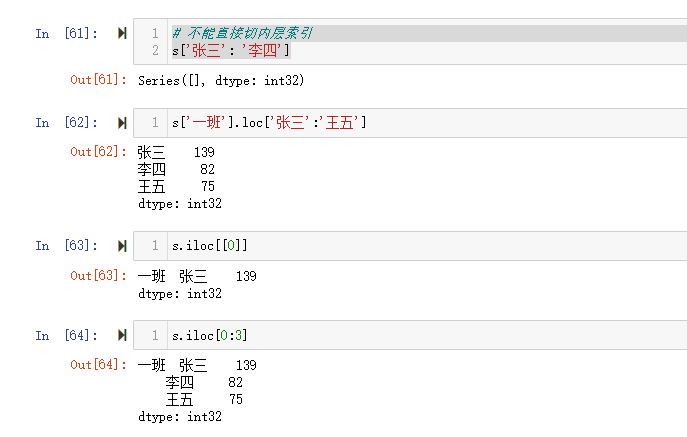
【极其重要】推荐使用loc()函数
注意在对行索引的时候,若一级行索引还有多个,对二级行索引会遇到问题!也就是说,无法直接对二级索引进行索引,必须让二级索引变成一级索引后才能对其进行索引!
索引的堆
stack()unstack()
索引的堆指的就是 多层索引中行索引和列索引的转化

1 | # 默认level 是-1 |
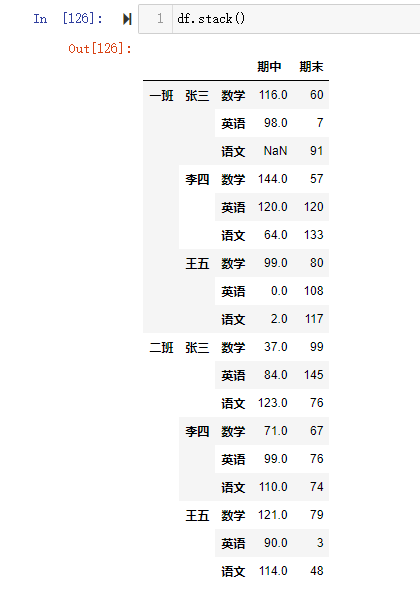
1 | df.stack(level=0) |
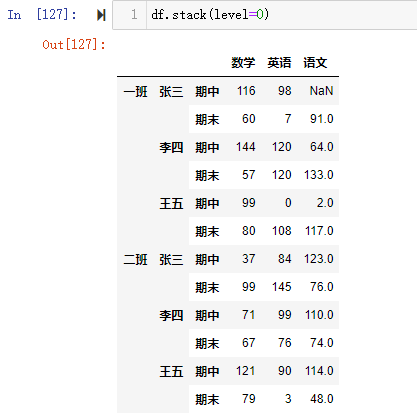
1 | df.unstack() |
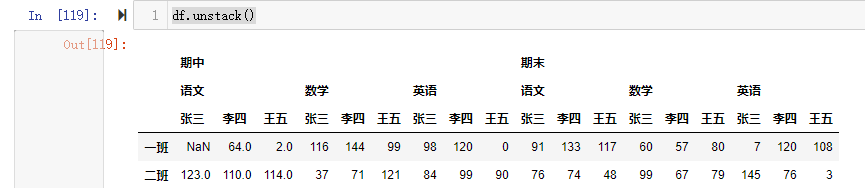
1 | 【小技巧】使用unstack()的时候,level等于哪一个,哪一个就消失,出现在列里。 |
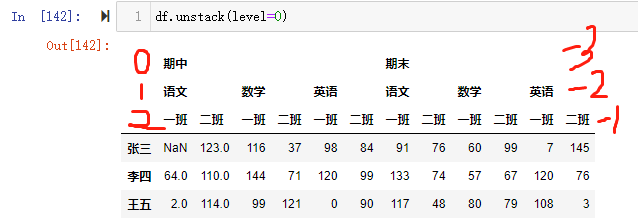
聚合操作
所谓的聚合操作:平均数,方差,最大值,最小值……
1 | sum / min /max / mean / std/ var/ prod/ median / percentile.... |
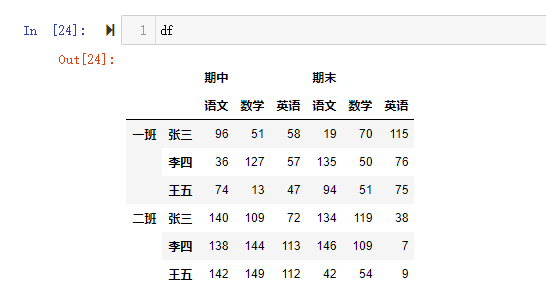
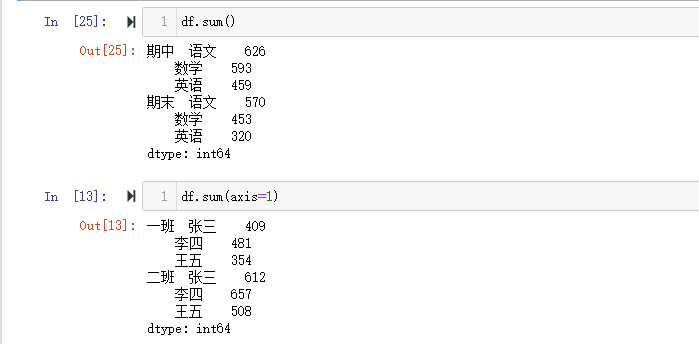
1 | # 一班二班,各科成绩的和. |
【注意】
- 需要指定axis
- 【小技巧】和unstack()相反,聚合的时候,axis等于哪一个,哪一个就保留。