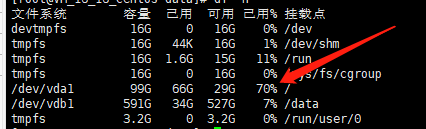
交换机VLAN命令
VLAN基本命令
1 | vlan 10 # 创建单个VALN |
1 | vlan 10 # 创建单个VALN |
1 | ospf 1 router-id 1.1.1.1 # 开启ospf.进程号为1手动配置Router ID |
1 | int g0/0/0 |
1 | ip router-static 0.0.0.0 0.0.0.0 |
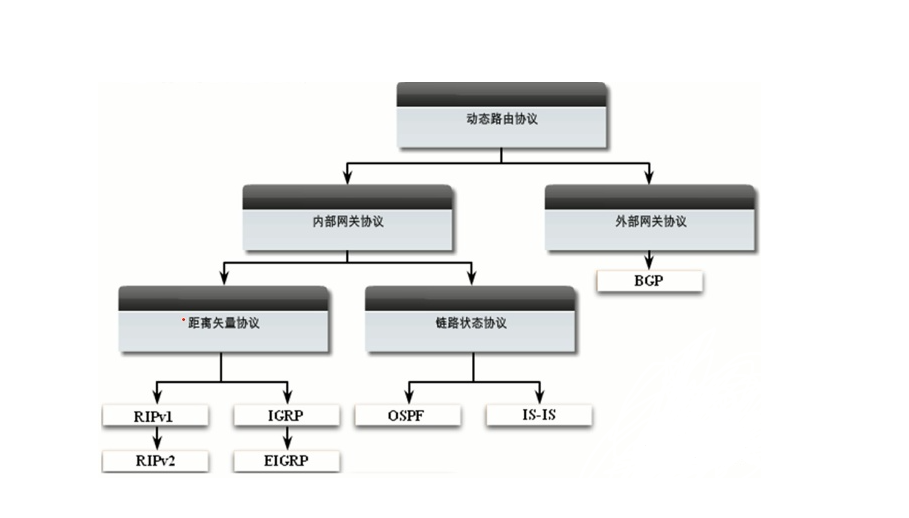
AS(自治域系统)内部使用内部网关协议; AS与AS之间使用外部网关协议
静态路由是指由用户或网络管理员手工配置的路由信息。当网络的拓扑结构或链路的状态发生变化时,网络管理员需要手工去修改路由表中相关的静态路由信息。静态路由信息在缺省情况下是私有的,不会传递给其他的路由器。当然,网管员也可以通过对路由器进行设置使之成为共享的。静态路由一般适用于比较简单的网络环境,在这样的环境中,网络管理员易于清楚地了解网络的拓扑结构,便于设置正确的路由信息。